If you've worked with distributed systems, you might have wondered why some focus more on consistency, while others prioritize availability.
In this blog, I'll explain why by exploring the CAP theorem. I recently came across this concept while reading "System Design Interview" by Alex Xu (you can find this gem in my Tech Library if you're interested), and I thought it'd be cool to share what I learned. So, let's dive in!
But what is the CAP Theorem?
Sounds interesting, right? Let's break it down and see what each of these guarantees means.
Consistency (C)
Imagine you're using a distributed system to manage your bank account. Consistency ensures that no matter which node (server) you connect to, you'll always see the same balance. In other words, all nodes see the same data at the same time. Pretty important when it comes to your hard-earned cash, huh?
Availability (A)
Availability is all about ensuring that every request receives a response, without guarantee that it contains the most recent version of the information. It's like when you check your social media feed - you want to see posts instantly, even if they're not the absolute latest updates.
Partition Tolerance (P)
This is the system's ability to continue operating despite network partitions (communication breakdowns between nodes). It's like when your phone loses signal but can still perform some functions.
The Tradeoff
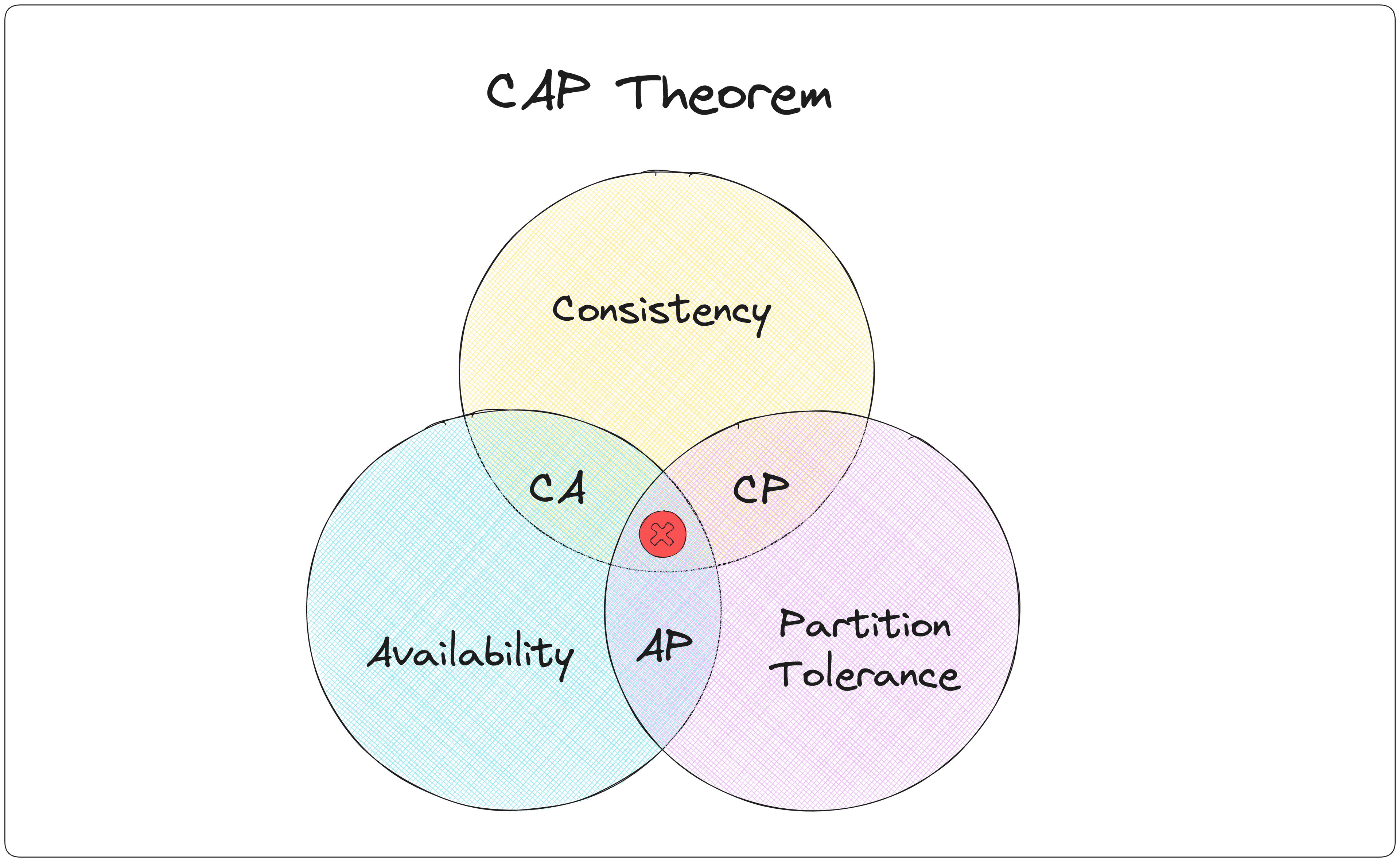
Now, here's where it gets interesting. The CAP theorem says we can't have all three - we have to choose two. Let's look at the possible combinations:
- CA (Consistency + Availability): Great for systems that can't afford network partitions. Think single-site databases.
- CP (Consistency + Partition Tolerance): Ideal when you need atomic reads and writes. Examples include Google's BigTable or MongoDB.
- AP (Availability + Partition Tolerance): Perfect for systems that can tolerate eventual consistency, like Amazon's Dynamo.
Real-World Examples
Let's put this into perspective with some examples:
- Banking Systems: These often choose consistency over availability. You wouldn't want to see different account balances on different ATMs, would you?
- Social Media Platforms: These usually prioritize availability and partition tolerance. It's okay if you don't see your friend's latest post immediately, as long as the service is always up.
Why Does It Matter?
Understanding the CAP theorem is essential when designing distributed systems. It helps you make smart choices about which properties to prioritize based on your specific needs. Is data accuracy your top priority? Or is it more crucial that your service remains available at all times?
PACELC
Just when you think you've finally understood CAP, along comes PACELC! PACELC is an extension of the CAP theorem that offers a more detailed view of the tradeoffs in distributed systems.
PACELC stands for:
- Partition tolerance (P)
- Availability (A)
- Consistency (C)
- Else (E)
- Latency (L)
- Consistency (C)
The theorem states: "In case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C) (as per the CAP theorem), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C)."
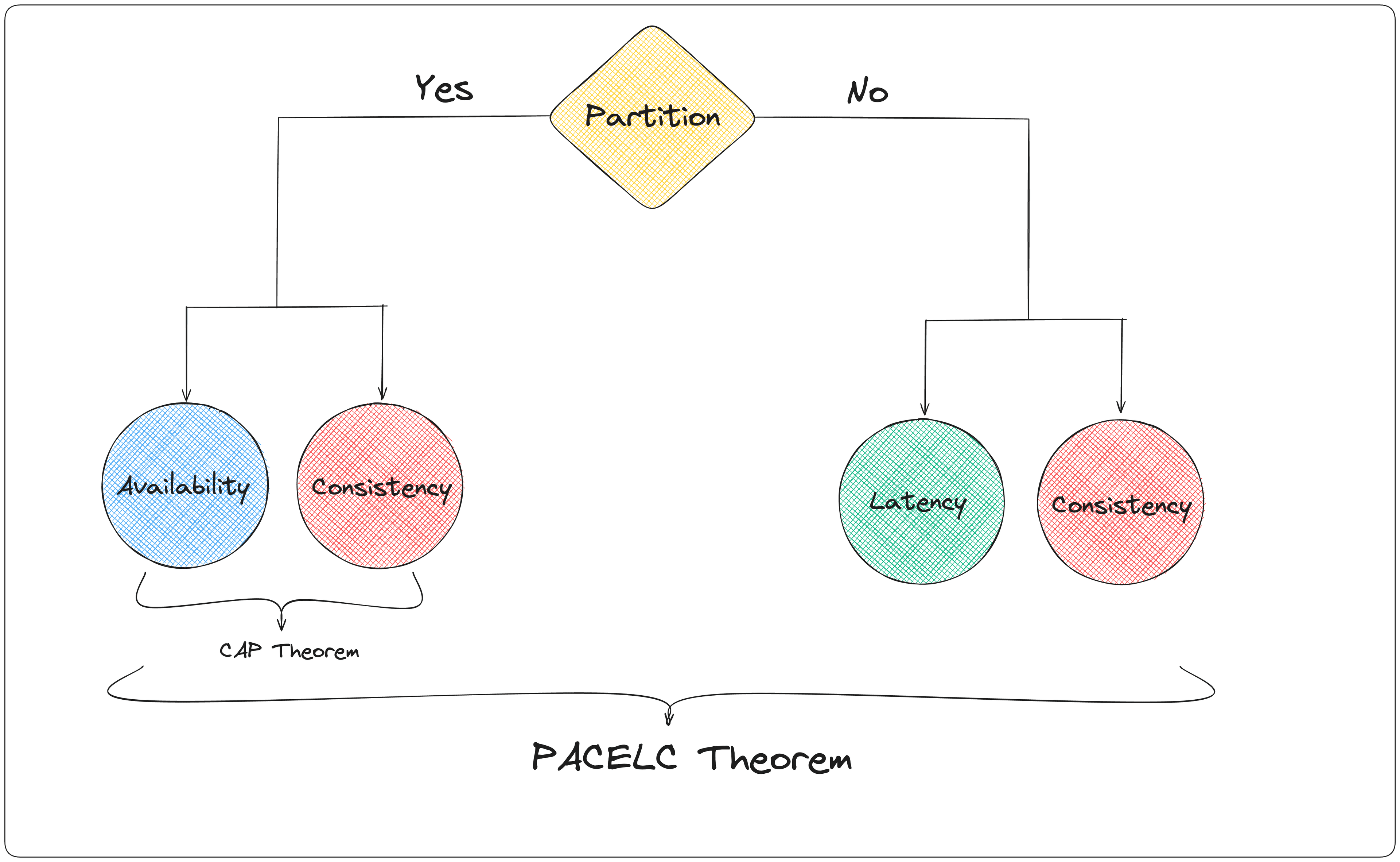
In other words, PACELC acknowledges that even when the system is operating normally (no partitions), there's still a tradeoff between latency and consistency. This gives us a more comprehensive framework for understanding the design choices in distributed systems.
For example:
- A system like MongoDB might be PC/EC (prioritizing consistency in both partition and normal scenarios)
- Cassandra might be PA/EL (choosing availability during partitions and low latency during normal operation)
Understanding PACELC can help u make even more informed decisions when designing distributed systems, considering not just how the system behaves during network partitions, but also during normal operations.
Conclusion
The CAP theorem isn't just some abstract concept - it's a fundamental principle that shapes the architecture of the systems we interact with daily. By understanding its implications, we can make better decisions in system design and appreciate the tradeoffs made in the apps and services we use.
Remember, there's no one-size-fits-all solution. The best choice depends on your specific requirements. So, next time you're designing a distributed system, ask yourself: which two out of three am I willing to guarantee?
Happy coding, and may all your systems be perfectly balanced (as all things should be)! 🚀